What a start for a blog to end up on the homepage of Hacker News on the first day (with a short post about Django UI). The good: it’s surprisingly easy to install a cache plugin to WordPress. The bad: this blog is not hosted on the Slipmat.io server (because I don’t want to install PHP on it) so I missed a great chance to stress-test it.
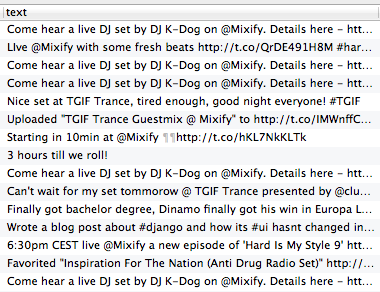
To stay with the topic on flying starts, I’ve been quietly readying the first Slipmat.io tool, a site for taking and making requests in Mixify events, for its official launch. I opened the site for public three weeks ago and I’ve been working on it ever since. I’m keeping detailed public release notes to keep the users updated and also for myself as a way to get a feel of the progress.
Most non-DJs and furthermore non-Mixify users probably have no idea what this tool actually does, so let me explain it quickly. Mixify is a Web site where DJs can play for a live audience by streaming sound (and possibly also video) from their computer to Mixify which distributes it to listeners. Listeners can join these live events and chat with the DJ and other listeners. Many DJs take requests but it can sometimes be cumbersome trough the small chat window that can update really fast if there are lots of listeners actively chatting. MixifyRequests is a site where a DJ can make a request event and get the requests in a nice, organised way with a easy to use admin controls for marking requests played etc. Users can also vote for each others requests and there’s a bunch of other features, too. So that’s the idea in a nutshell.
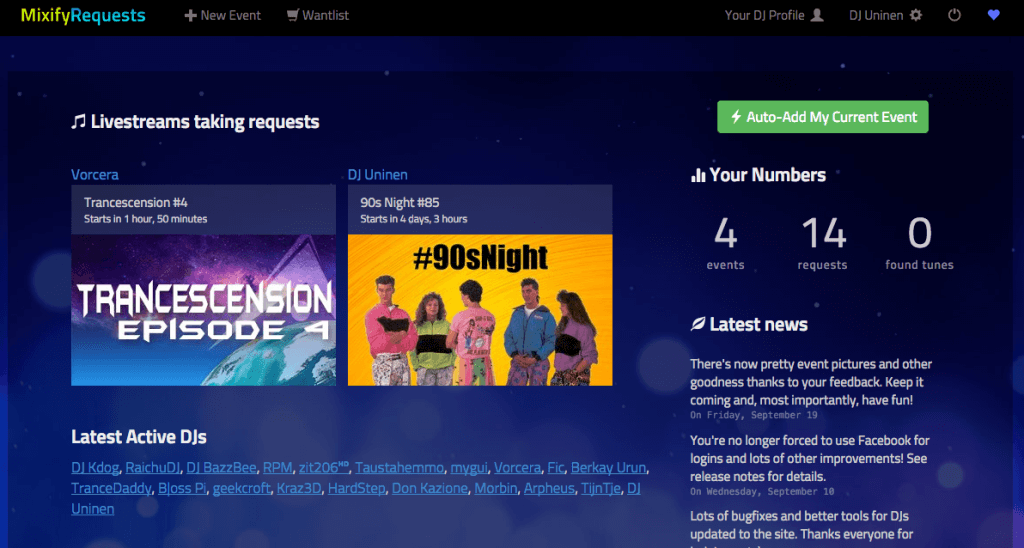
I did the first part of the development in one 10 day sprint, with the idea of getting the first alpha version online in whatever state it would be after 10 days. (Because real developers ship.) The first release had one big showstopper-bug[^1] which was due to my lazy testing of Facebook sign up process, but otherwise everything worked fine.
[^1]: Where users who signed up everywhere but from the homepage would get a 500 error after first login because the login view respected ‘next’ parameter that would redirect them past the view that created an app-spesific user profile of which everything on the site assumed to be there. Thanks to Sentry I was informed about the bug immediately and got a hotfix in place in about 20 minutes but it had already affected dozens of users of which few of them didn’t come back that first night.
I decided to do kind of a soft launch by only telling about the site to few selected DJs and by placing a disclaimer on top of every page with a note saying “This site is not officially launched yet. Use it and have fun, but please do not advertise this yet in bigger scale. Thanks!“. So far this has worked really well and the userbase has been steadily growing at a rate of about 1-3 new users every day. Thanks to a small number of real users actively using the site, I’ve gotten loads of good usage data, and most importantly, I’ve been able to find and fix good number of bugs emerging from situations only real users can get to. (It never ceases to amaze me how actual users always find ways to break code that was supposed to be tested really well.)
After the first sprint and the initial production push I changed the development cycle more towards daily productions pushes with the help of feature switches. Last week I sent out an email to all active DJs of the site asking volunteers as future betatesters. Got a few and now I can test and roll out new features in a controlled manner independently of production pushes. Feature switches enable me to keep the development branch in Mercurial very close to stable branch and push bugfixes, not yet polished code and new features on the site daily without exposing anything to the public before the code is ready and tested (live with betatesters). When I want to publish a new feature, I go to the admin, flip a switch, and it’s live. Boom! Also, if there are any problems, I can just as easily flip the feature off again, and fix the problem with no hurry. Feature switches are awesome. There are lots of different apps for Django for doing this, I chose Gargoyle (mainly because couldn’t figure out how to get the newer version called Gutter working). Big props to Disqus folks for yet another awesome Open Source app.
If you’re interested in following the development of Slipmat.io site by this lone music loving Django developer, check out @slipmatio on Twitter, Slipmat.io on Facebook and, of course, keep in touch with this blog. And if you have been, thanks for reading this far!
(This post was originally posted to my other blog called Spinning Code.)